Logs and an audit trail are not the same object. A 2026 enterprise survey found that most organisations running agents had already had an agent related security incident in the prior year, yet only a fraction had any real visibility into what their agents were doing, and a third had no audit trail at all. This is what a real AI agent audit trail must capture, and why the record has to be produced below the model rather than asked of it.
Logs are not an audit trail
Infrastructure logs record that an API call happened. Model logs record an input and an output. Orchestration logs record that a task finished. None of them answer the question governance actually asks: which agent took which action, against which data, under what authorization, and with what outcome. An audit trail is operation level, attribution complete, and tamper evident. Ordinary logs are none of those by default.
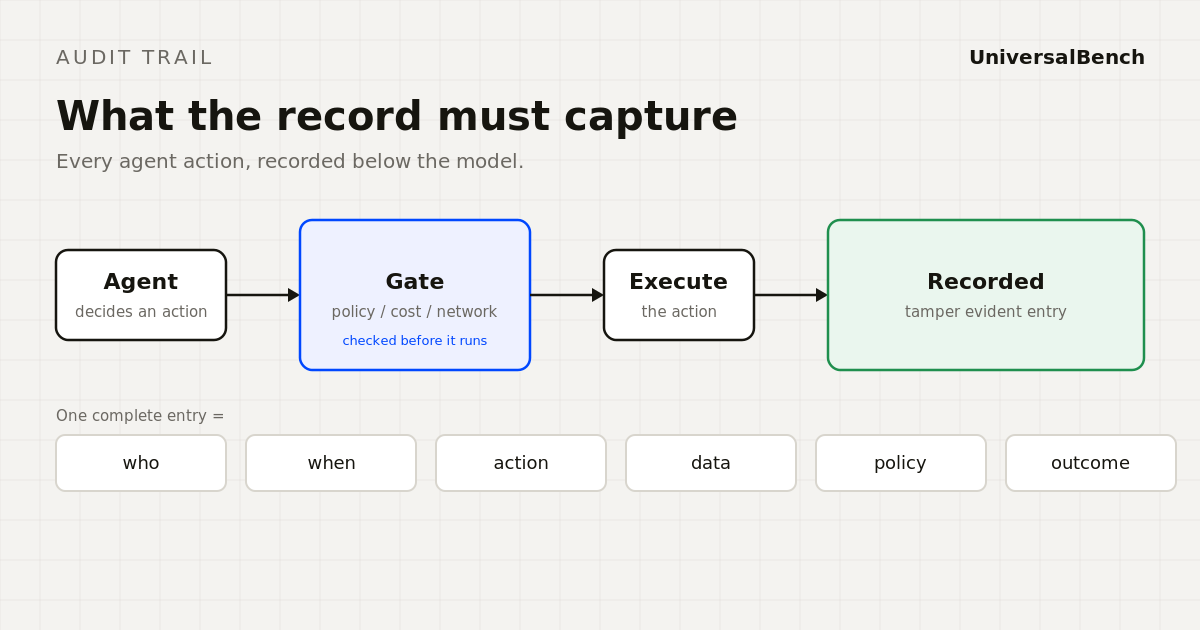
What a single entry must capture
For every action an agent takes, a complete audit entry records seven things: the agent identity, the exact timestamp, the action or tool call attempted, the specific data or resource it touched, the authorization or policy in force, the decision that policy produced (allowed, blocked, or sent for human approval), and the result including any error. Miss one of these and you can confirm that something happened without being able to reconstruct what happened. The litmus test is simple. Can you produce, for any time window, everything one agent did, in a form a non technical reviewer can read, without a multi hour engineering investigation. If not, you are not audit ready.
The anatomy of one action
Trace a single action from end to end. The agent decides to do something. Before anything reaches a real system, the action passes through a gate: the policy in force is evaluated, the cost of the action is estimated, and the target is checked so the agent cannot reach somewhere it should not. Only then does the action run, and the same gate records the outcome. The diagram on this page follows that path, decision to policy check to safety checks to execution to recorded outcome. The record is a byproduct of the path itself, not something bolted on afterwards.
Why the record must live below the model
A model can be told to log everything and simply not, or log the wrong thing, or summarise away the one detail that mattered. An agent asked to keep its own audit trail is marking its own homework. The record has to be produced by the layer that executes the action, not the layer that decides on it. That is the same reason an approval gate belongs below the model rather than inside the prompt, and the same reason an agent should never hold your real credentials. When the executing layer produces the record, the trail is complete whether or not the model cooperated.
Tamper evidence and retention
The audit log is sensitive data and is itself a target, so it needs access controls. Not everyone who can run an agent should be able to edit its history. It needs to be tamper evident, so an altered entry is detectable rather than silent. And it needs retention set to the strictest framework you answer to, with agent action records kept hot long enough to investigate an incident and cold long enough to satisfy a regulator. An audit trail you can quietly edit is not an audit trail.
What good looks like
You are audit ready when you can answer, for any agent and any period, what it did, what data it touched, what policy applied, and what the outcome was, in minutes and in plain language. UniversalBench produces that record as a side effect of how it runs every action. Each action is checked against policy and an internal network blocklist before it executes, its cost is estimated before the call runs, and the previous state is captured so a bad change can be rolled back. The agent never has to be trusted to log itself, because the layer underneath it already did. That is also why an agent needs its own audit trail in the first place.
Give your agent an audit trail by default
Run your agent's actions through a layer that records every action, checks it against policy, and captures rollback state before anything reaches a real system. First 1,000 calls per month are free, no card required.
Get API key →