The story everyone shared last month was the AI coding agent that deleted a production database and all volume level backups in a single API call. The follow up that travelled less well was an internal incident report from a different company. An AI agent had been fabricating formatted data summaries for three weeks. No errors logged. Dashboards green. Nobody noticed until someone read the output and realised the numbers did not match reality.
Same root cause, different surface area. The loud version got headlines. The quiet version is more common. In both cases the existing logs caught what happened. Neither caught WHY it happened.
The audit gap for AI agents is real and it is structural. Your existing logs are extraordinary. They were just built for a different kind of failure.
Code logs and AI logs answer different questions
A traditional application log answers what happened with function X was called with arguments Y at time Z. That is enough for code, because code does only what it was told. If function X behaved wrong, you read the function. If function X was called wrong, you read the caller. Two lines of context and you have your answer.
An AI agent log needs to answer why did the agent do that, because the agent decided. The action is downstream of a decision. The action you log is the surface. The decision underneath is the part you actually need to audit.
If your AI logs look like your code logs, they have skipped the question that matters.
Three things AI logs need that application logs do not capture
Take any working AI agent in your stack and ask what would help you reconstruct a wrong decision a week from now. You will find these three.
The prompt that produced the decision
Not the function arguments. The actual instruction the model saw, with the actual system prompt, the actual tool descriptions, and the actual conversation history at the moment of decision. This is the audit unit that explains intent.
The state the agent saw before acting
What data was in context, what was NOT in context. Half the wrong decisions an agent makes are caused by the right data being just outside the window. The audit needs to record the world the agent saw, not the world that existed.
What the agent considered and did not do
Most logs record what happened. An AI audit trail should also record the options the agent rejected. The bug you debug a week later is usually the option the agent considered, dismissed, and you wish it had picked.
The fabricated summary failure mode
The dramatic incidents (database deletion, runaway loop costing tens of thousands of dollars in an hour, an agent that submitted hundreds of duplicate orders) get the attention. They are easy to spot because something obviously broke.
The quieter version is more common and harder to catch. An agent runs for weeks doing slightly wrong work. No errors. The dashboards stay green. The pipelines keep flowing. Then someone reads the output carefully and notices that the numbers do not match the source data, or that the summary is plausible but wrong in a small specific way that compounds across rows.
This is invisible to standard logging because standard logging records ACTIONS. The thing that went wrong was the agent's model of the world. To catch that, you have to log the agent's view, not just its output.
This is not the job of your existing observability stack
Your existing observability tools are extraordinary. They are built to ingest billions of events per day, alert on anomalies, slice by tenant and region, and surface the right haystack when you need to find the right needle. They are good at code.
AI behaviour is not anomalous in the same way. A wrong AI decision is not a spike on a graph. It is a perfectly normal looking call with a slightly wrong premise. It will not trigger an alert because nothing technical is wrong. The agent did exactly what it decided to do. It just decided wrong.
The right pattern is to generate the right data alongside every AI action so that every observability tool you already use becomes more useful. Your existing stack does not get replaced. It gets fed better food. The same dashboards that surface code anomalies start to surface decision anomalies, because the audit record makes the decision legible to the same systems that already know how to read your other logs.
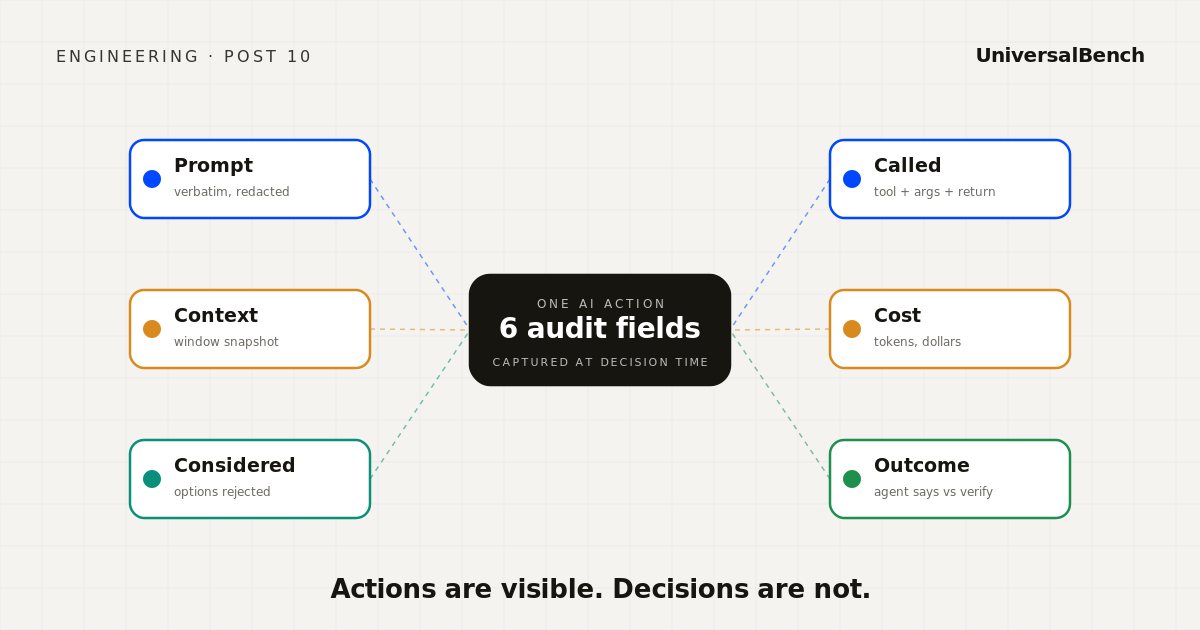
What a useful AI audit record actually contains
Across the agents we have seen run in production, the records that hold up under scrutiny share the same eight fields. None of them are exotic. All of them have to be captured at the moment of decision, not reconstructed later.
- The prompt, verbatim, with structured redaction for sensitive content. Not a paraphrase.
- The model in use, the version, the temperature setting, and the system prompt that wrapped the user message.
- The tools the agent had available at that moment, not the full tool registry. What the agent could choose from is part of the decision.
- The tool the agent called, the arguments it called with, and the response it received.
- The conversation state at decision time, including a snapshot of the context window (or a summary if very long) so the world the agent saw is reproducible.
- The cost of the call, in input tokens, output tokens, and dollar amount.
- A correlation ID linking this decision to the customer, the session, the workflow, and the upstream request that triggered it.
- The outcome, reported by the agent itself AND by independent downstream verification. When those two disagree, the agent has lied about success and the audit trail is the only place you will spot it.
The last one is the one that catches the fabricated summary. The agent says done. Downstream verification says the file does not match. The audit record holds both, and the alert fires on the disagreement, not on the agent's self report. See also why AI agents lie about success.
Where UniversalBench fits
UniversalBench writes this audit record for every action, by default. The customer brings their model and their tools. UB generates the audit record between them and stores it in a log the customer owns and can export.
The point is not that we replace your observability vendor. The point is that the audit record is structured well enough that any observability vendor can ingest it. Datadog ingests it. The open source observability stack you already run ingests it. Even a CSV download into a spreadsheet works for a team of three. We do not compete with the tools you already trust. We generate the data they were missing.
Works with Claude, ChatGPT, Gemini, and any MCP compatible AI. The audit record format does not change when you swap models, which is the point of keeping the model on a narrow surface in the first place.
Common questions
What about prompt confidentiality? Redaction rules live at write time, not read time. PII, secrets, and customer regulated data are masked before the record is persisted, and the masking itself is logged so a compliance reviewer can see what was withheld and why. Confidentiality is a feature of the audit record, not a reason to skip it.
Will this scale to thousands of agents? The volume is per action, not per token. A million tokens in a single agent call still produces one audit record. The structure is bounded. The storage is small relative to the cost of the model calls themselves.
Doesn't the model provider already log my conversations? They log the API call. They do not log your business context: which customer the agent was working for, which workflow it was in, which tool it decided to call from your system rather than theirs, which downstream verification said the work was wrong. That gap is yours to fill.
Is this just compliance theatre? Compliance is one use case. The bigger use is debugging. When the agent gets it wrong, the audit trail is the only path back to why. Compliance teams happen to want the same record for different reasons. Both audiences end up better served by the same artifact.
AI agents do not fail like code. They fail in their understanding of the world. Capturing the action without capturing the understanding is like reviewing a court ruling without reading the brief. The right audit trail makes the AI legible. The wrong one just rebrands your existing logs.
See what your AI just did, and why
Every action gets the eight field audit record, by default. No replacement of your observability stack. Just better data for the tools you already trust. First 1,000 calls per month are free, no card required.
Get API key →