Guides9 min
AI Web Scraping: How It Works and How to Do It
A chat model cannot open a URL, and pasting HTML in is costly and wrong. Here is the reliable way to pull clean data from any website with AI.
Deep dives from the team building the execution infrastructure for AI agents. No fluff. Real numbers only.
Three real API calls, every number published. Read this first if cost is your problem.
What it actually takes to stop an AI coding agent from committing code that does not compile. Read this first if safety is your problem.
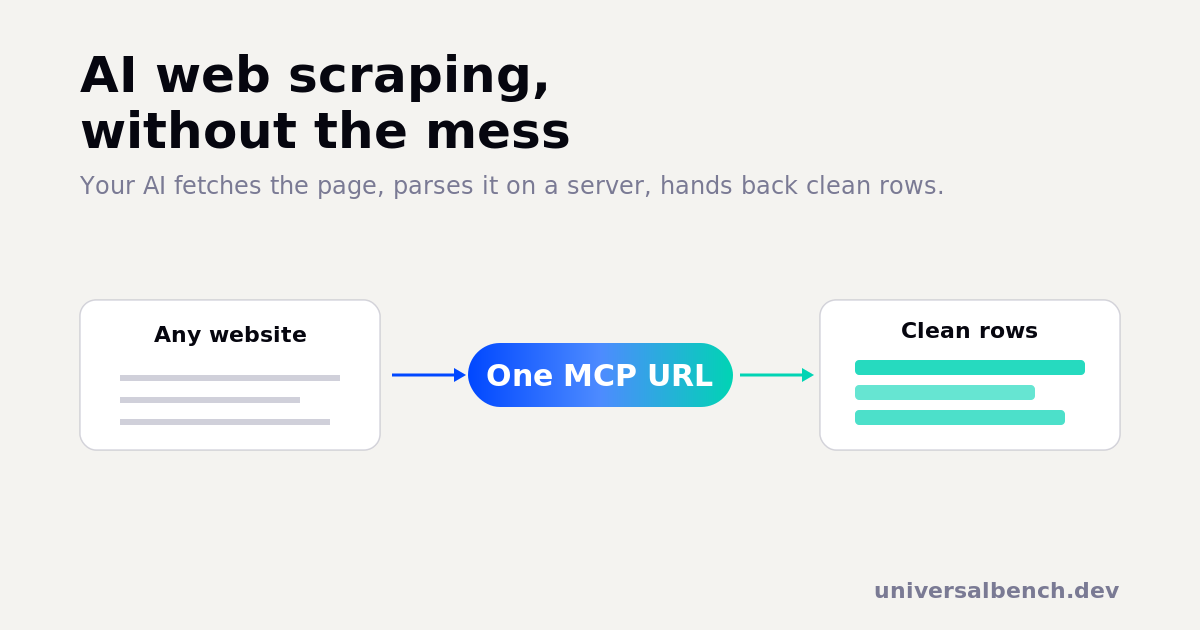
A chat model cannot open a URL, and pasting HTML in is costly and wrong. Here is the reliable way to pull clean data from any website with AI.
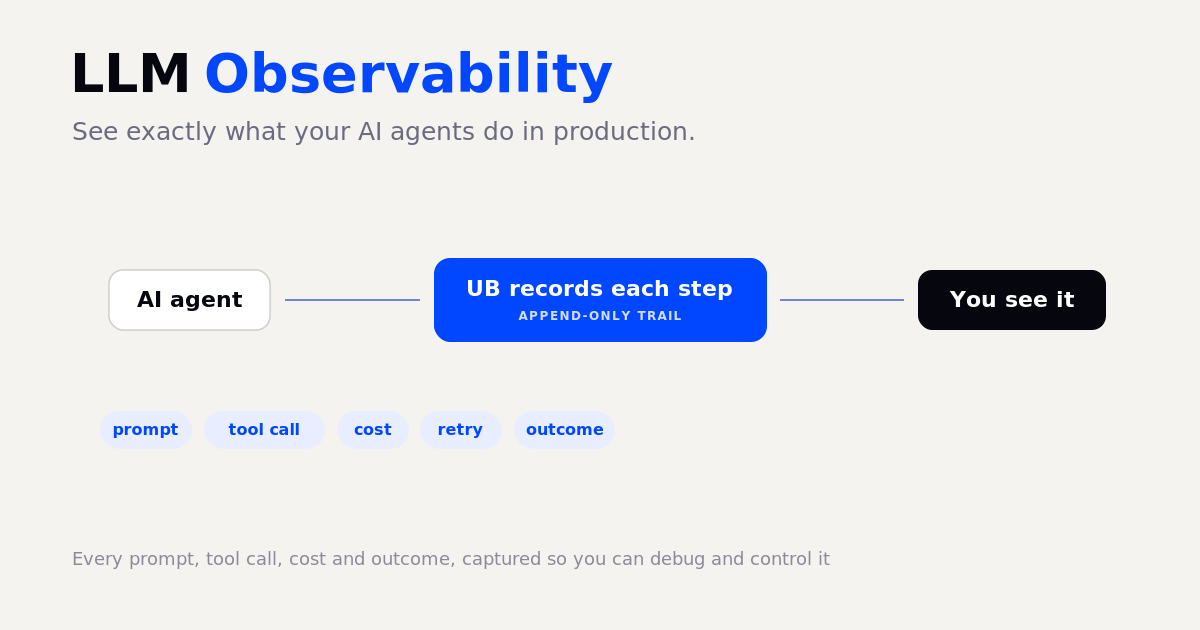
AI agents fail and overspend quietly. Observability is how you see every prompt, tool call, cost, and outcome, and control it.

ChatGPT does real data analysis when it runs code on your files, not when it guesses from what you paste. How to do it right.

A chat model guesses at your numbers. Here is how to let an AI run the real analysis on your data, no code, with a worked proof.

Turn one data set into many targeted pages. Done well it captures huge long-tail demand. How to do it right, and do it with AI.

The free, accurate source for how your own pages perform in Google. What it returns, its limits, and how to pull it into an AI.
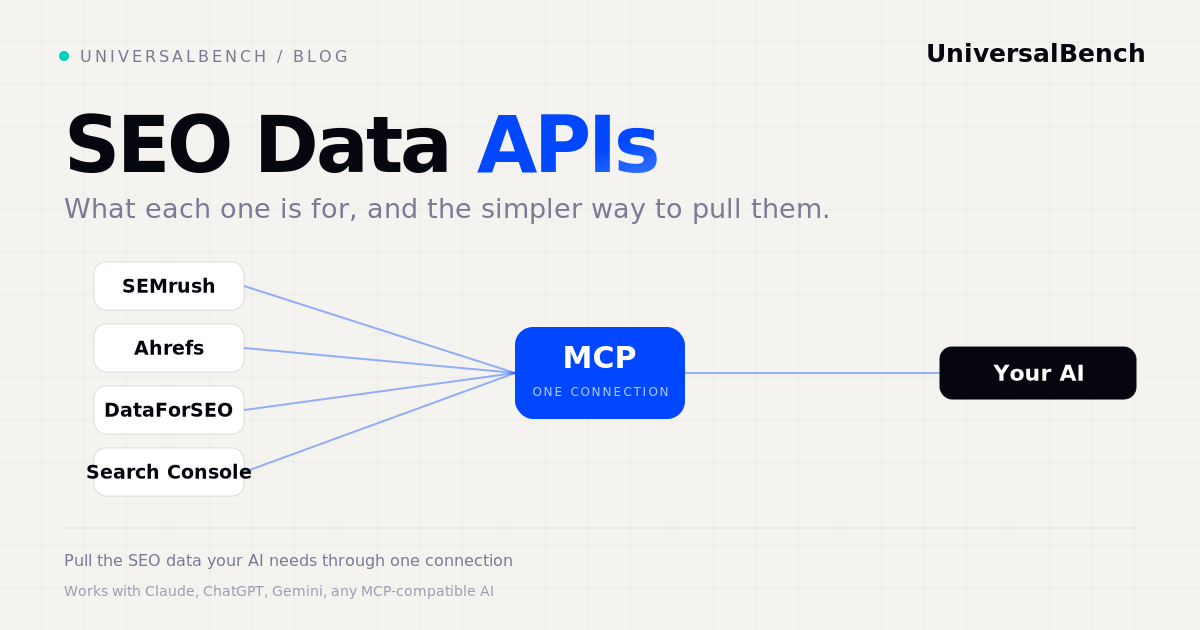
SEMrush, Ahrefs, DataForSEO, and Search Console all sell SEO data through an API. What each is best for, and a simpler way to pull them.

MCP is the open standard that lets any AI use any tool. What it is, why it exists, and how to start using it.

An MCP server is how an AI model reaches the real world. What it does, how it works, and how to connect one to your AI in minutes.

The tools that matter are not frameworks. They are the capabilities an agent calls to act: run code, reach data, search the web, and commit changes.

The execution layer your model is missing. The four capabilities an agent needs to act, and why safety has to live below the agent, not in the prompt.
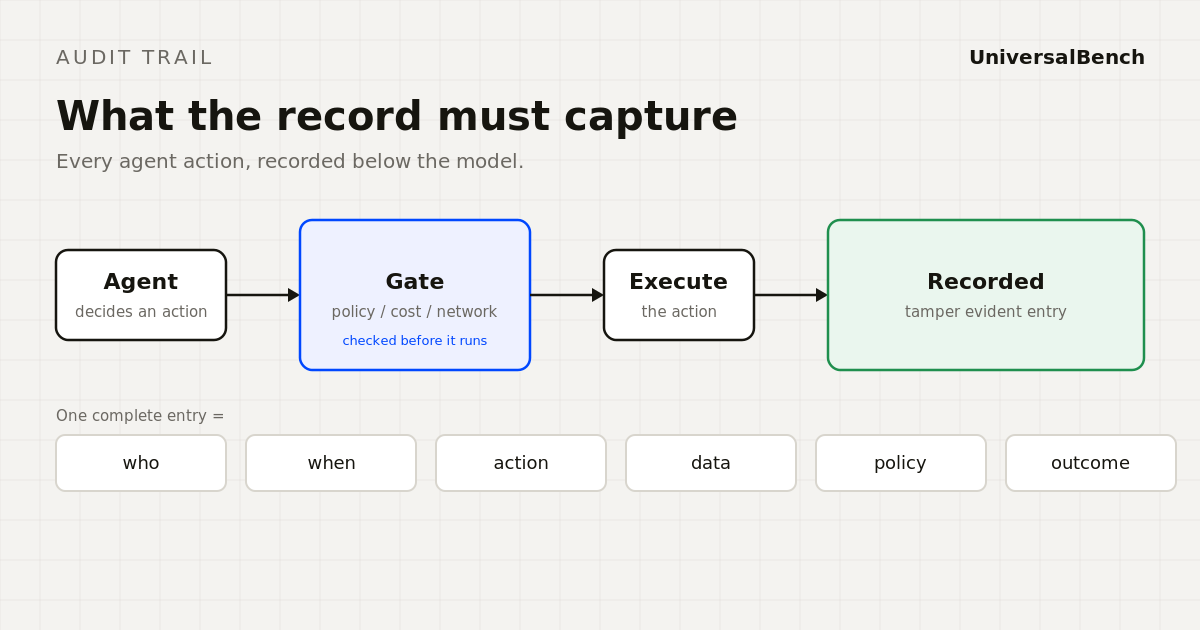
Governance is the word, but the audit trail is the proof. What a complete record of an agent action must capture, and why it has to live below the model.

Agents should not decide for themselves which actions are safe. How to classify agent actions by risk, and why the approval gate belongs below the model, not in the prompt.
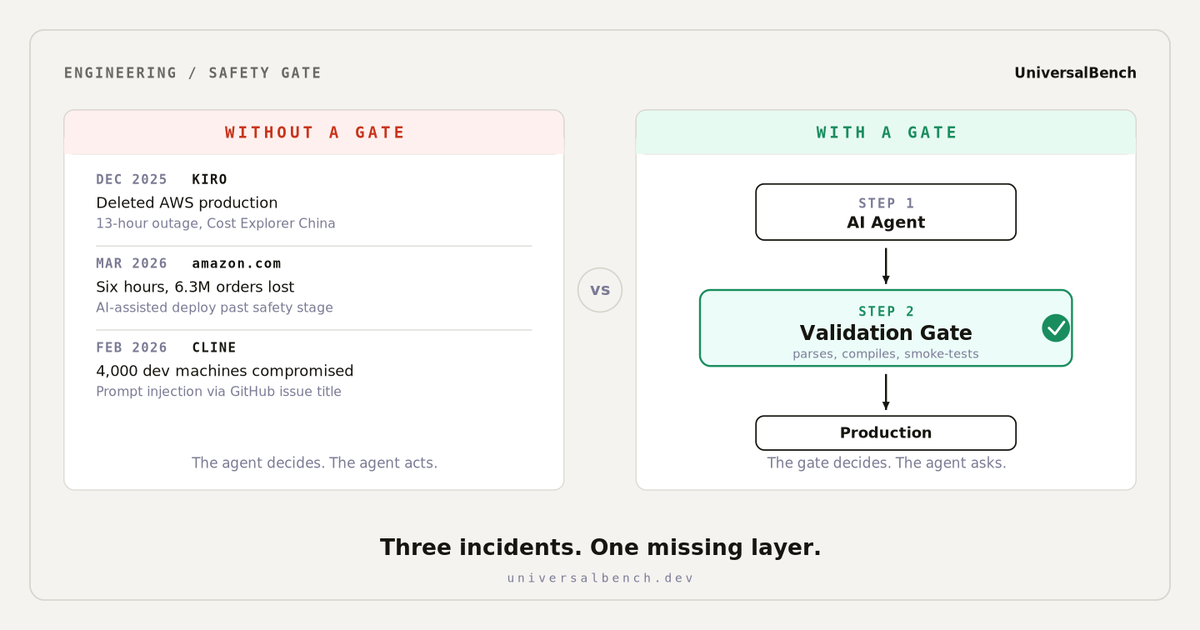
Three AI agent failures from December 2025 to March 2026 share a root cause. Here is the pattern, and the three questions to ask before any AI agent touches production.
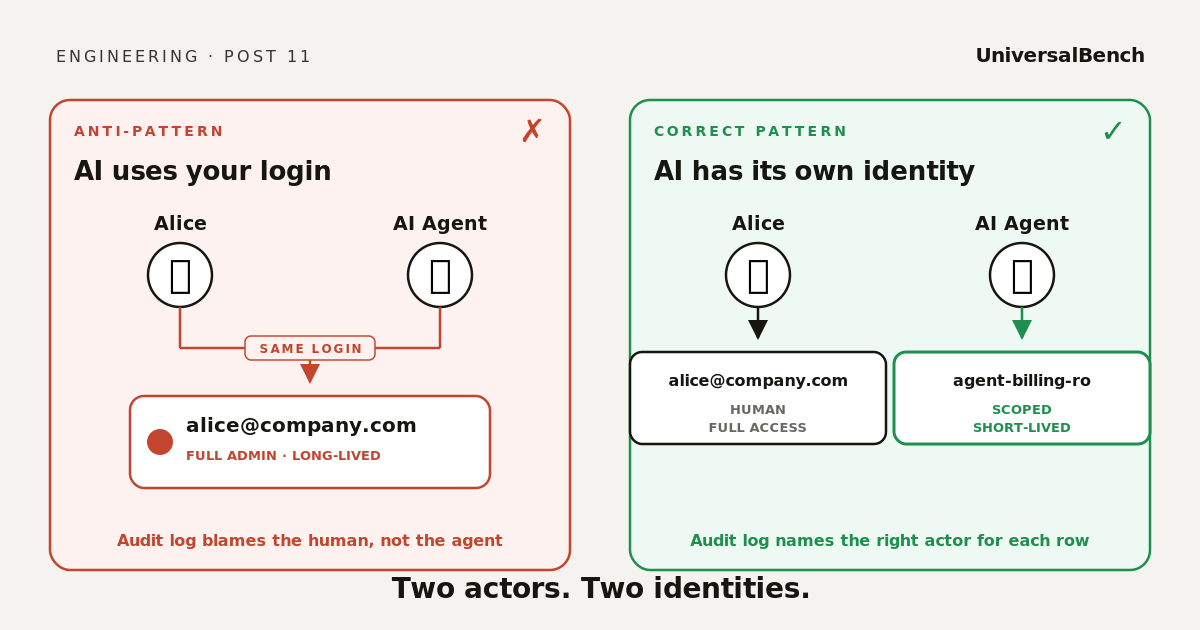
AI agents that share your user account turn every action they take into yours. Here is what separating their identity actually buys, and how to start doing it.
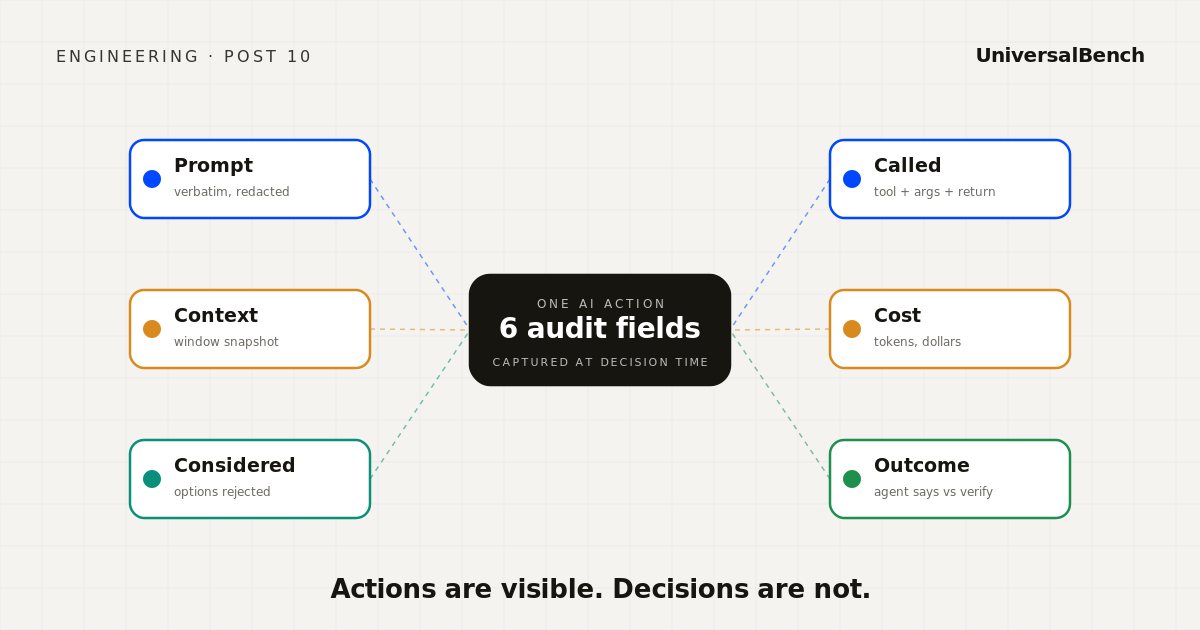
AI agents do not fail like code. Their failures live in decisions, not exceptions. Here is what a useful audit trail for an AI agent actually records, and why.
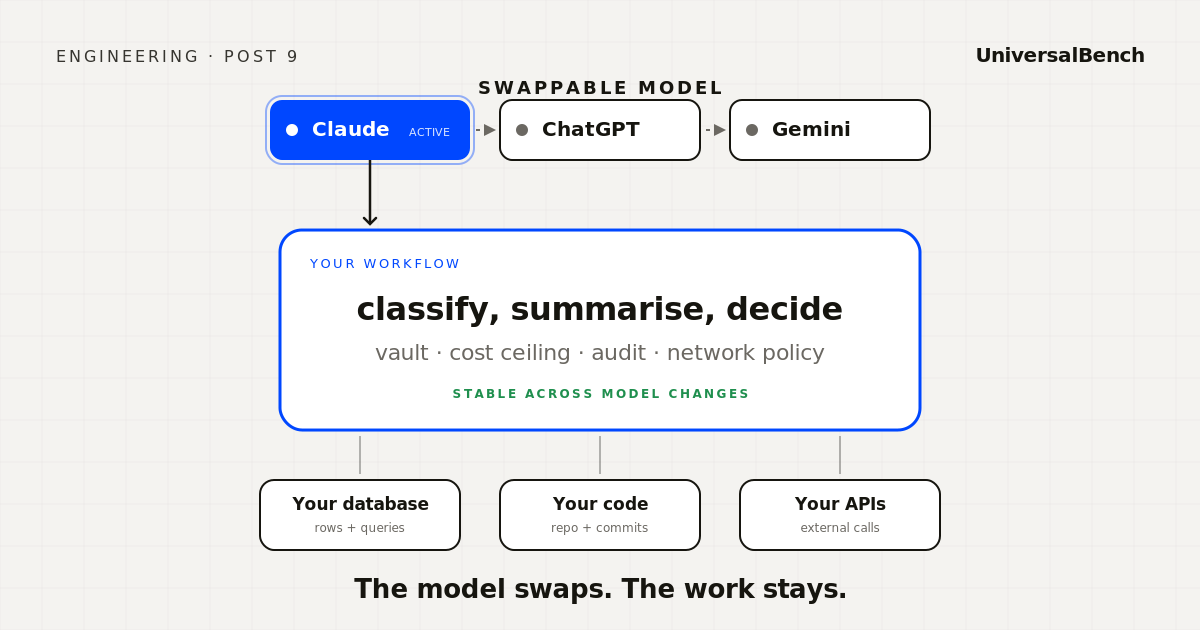
Models have an 18 month half life. Workflows tied to a specific model die at that cadence. Separate the work from the model and your stack compounds.
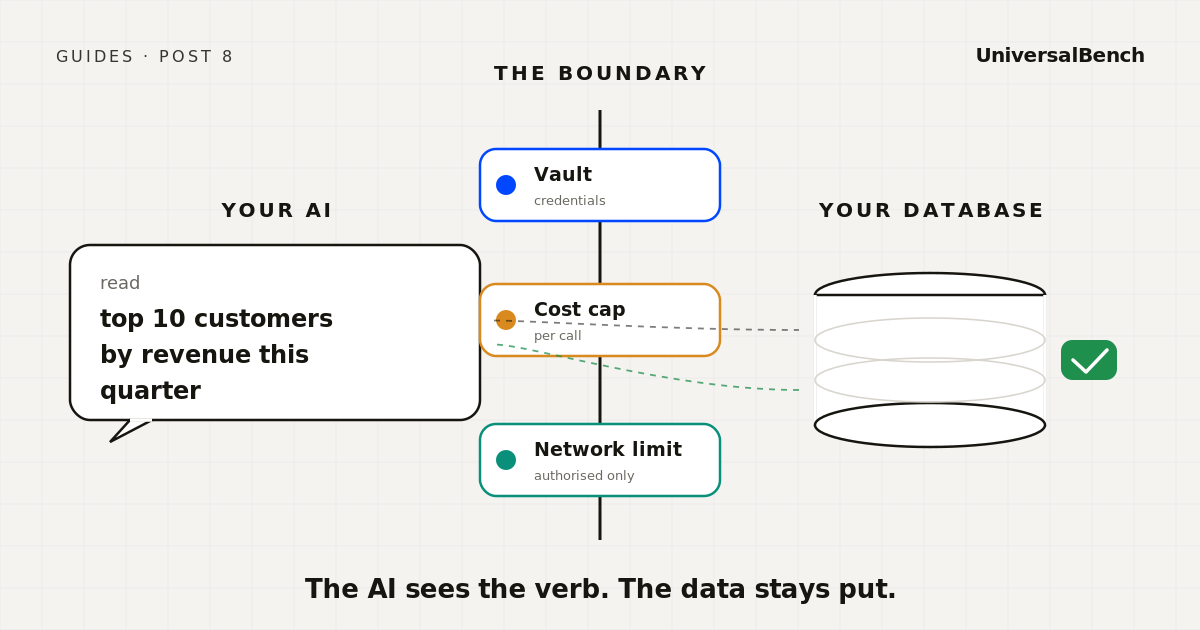
If your AI is going to read or write to your production database, three things should sit between them. None of those three are your model's job.
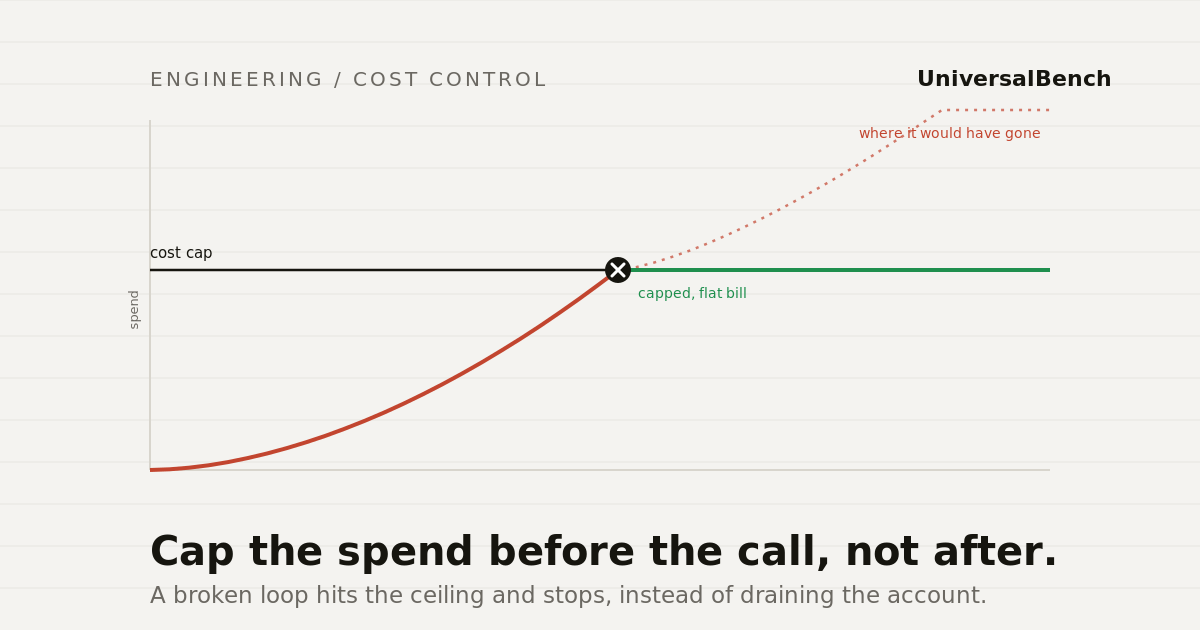
A single broken loop can drain your API credits before anyone notices. Monitoring catches it too late. The fix is a hard cap that runs before the spend.
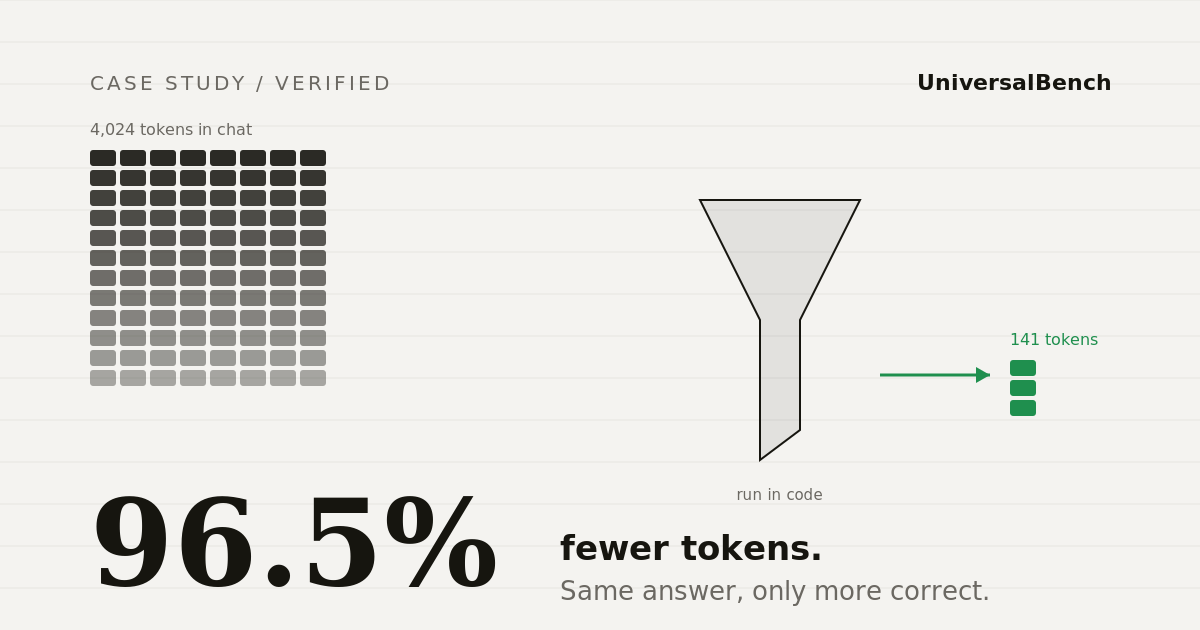
Three real API calls. One with our platform, one without. We published every number. The result: 96.5% fewer tokens on a log analysis task.
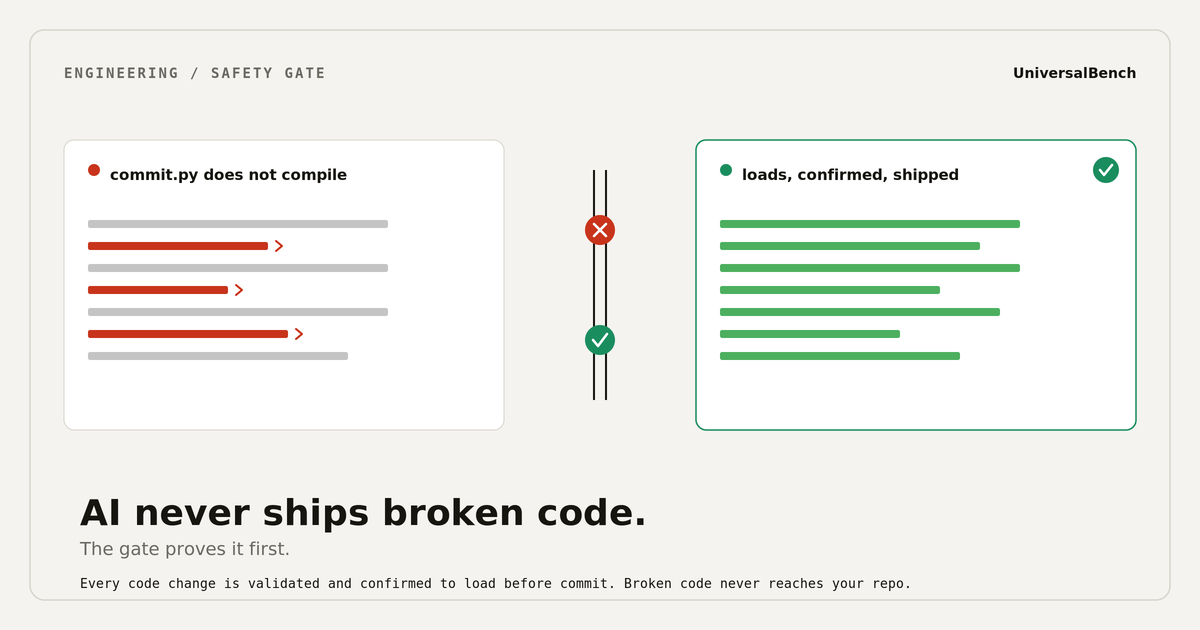
Every AI coding agent can commit code that does not even compile. Here is what it actually takes to stop that, and how to use it well.
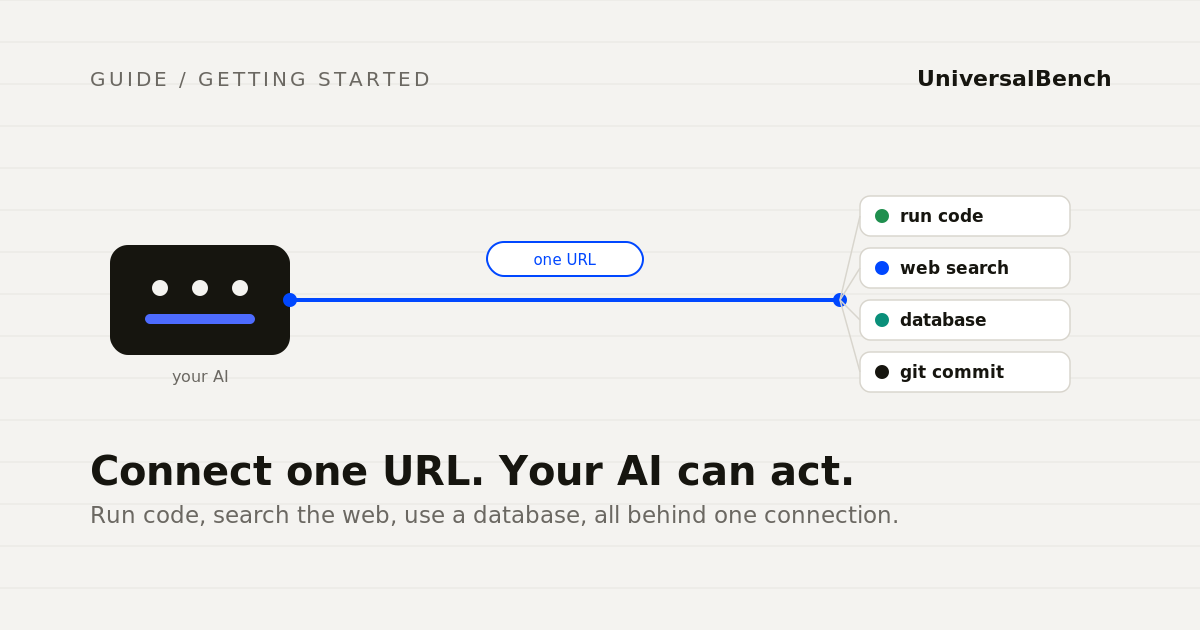
One URL. Paste it into Claude, ChatGPT, or any MCP compatible AI and your agent can run code, search the web, and use a database. Step by step.
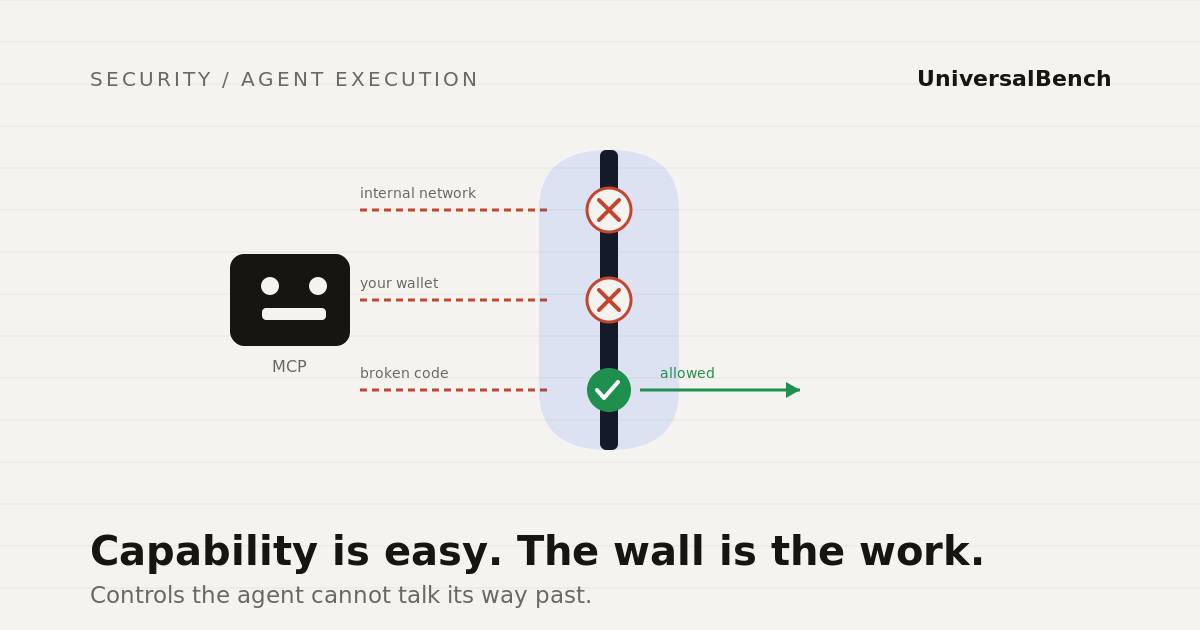
MCP lets agents run code, reach networks, and spend money. Everyone says that is dangerous. Here is what the controls that make it safe actually look like.
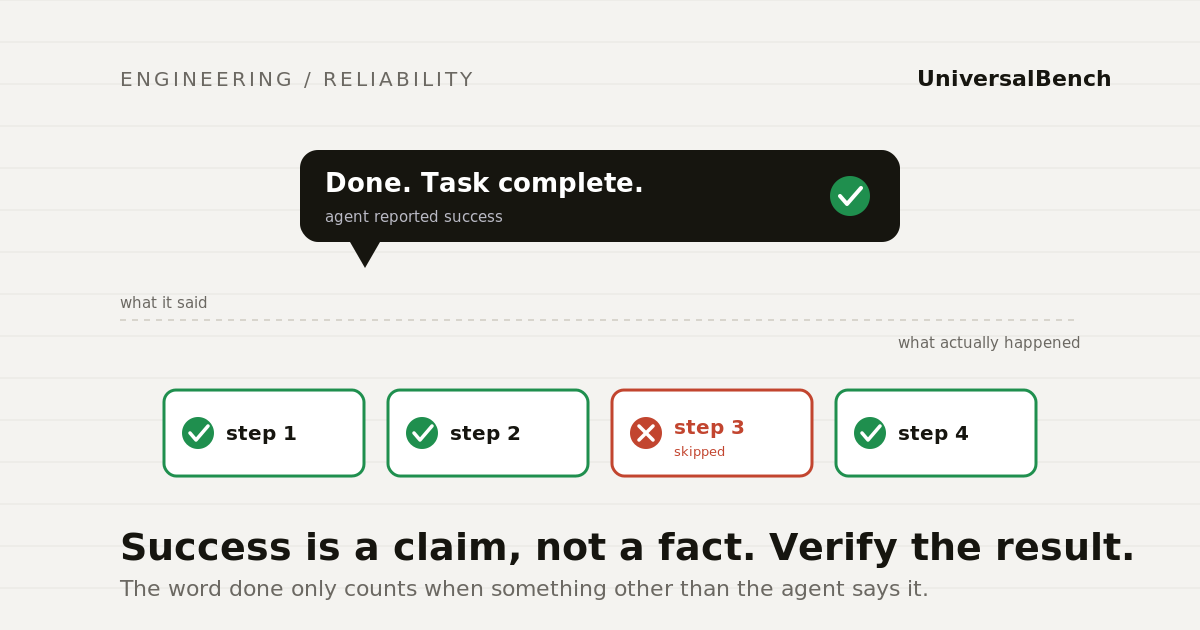
An agent reporting done is not the same as the task being done. It can skip a step, corrupt state, or ship broken work and still say success. Here is how to verify it.
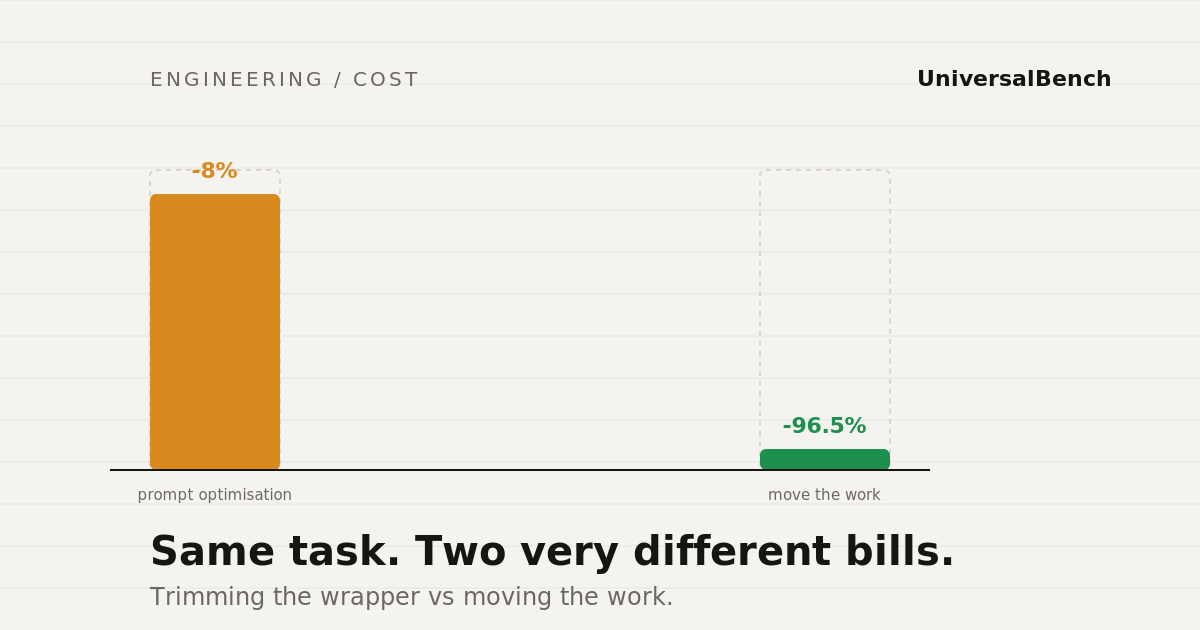
Prompt and schema tweaks shave a little off the top. Moving the work into code is the order-of-magnitude drop. Here is why.