Open any developer feed from the past six months and you will see the same conversation. Someone built a beautiful AI workflow against last quarter's flagship model. Six months later a new model lands that is cheaper, smarter, and faster, and they spend a week rewriting the workflow to take advantage of it. Then another model lands. Another rewrite.
This is not anyone's fault. The models really are getting better fast. The race between Anthropic, OpenAI, and Google is good for everyone. The question is whether your workflow rides that race or gets crushed under it.
The answer turns out to be architectural. Some parts of your workflow naturally belong to the model. Most parts do not. Knowing which is which is the difference between a workflow that compounds across generations and a workflow that needs an 18 month rewrite cycle.
Three things tied to a model that probably should not be
Take any working AI workflow you have today and look at where the model is mentioned by name. You will almost always find these three places.
The prompt format
Each model has its own preferences for system prompt placement, tool use formatting, and structured output schema. Swap models and half of the prompt becomes lukewarm at best.
The tool calling shape
Function call schemas differ between providers. Tools wired up for one model rarely work byte for byte on another. The function bodies survive. The wiring does not.
The auth and SDK path
Each model has its own client library, key shape, billing dashboard, and rate limit headers. Switching means changing all of that, in one weekend that does not feel like progress.
These three are real friction. Anyone who has tried to swap models in a half-built system knows the pain. But notice what they have in common. They are all about HOW you talk to the model, not WHAT you are doing.
What stays the same when you swap models
The work itself does not change. The customer database does not change. Your credentials do not change. The cost ceiling for any single call does not change. The audit trail of who asked the model to do what does not change. Whatever happens on the other side of the model, the side that touches your systems, your data, your money, is provider agnostic by nature.
This is the asymmetry. The model specific stuff is small in volume but loud in feel. The model agnostic stuff is most of the actual work but quiet because it just keeps working.
If you build the loud stuff so it is easy to swap, and you keep the quiet stuff out of any single model's gravity well, your workflow gets cheaper to maintain every quarter.
Switching is not the point. Optionality is.
Most developers reading this will not actually switch models very often. Once you find a model that fits your taste and your task, you tend to stay. The point of portability is not switching. The point is what happens when you do not switch.
A workflow that could swap models but does not is a workflow whose owner can negotiate. They know they could move. The model provider knows they could move. That keeps the relationship healthy. It keeps pricing fair. It keeps the conversation about features, not lock in. It also means when a meaningfully better model lands, you can take advantage of it in days instead of a quarter.
In other words, optionality benefits you AND benefits the model provider you currently use, because it pushes the whole market to compete on the right axis. A healthier market for governance and portability grows the market for intelligence, not the other way around.
This is not just for Fortune 500
There is a temptation to read all of this and think it is enterprise paranoia. It is not. AI-first startups feel the pressure to be portable faster than enterprises do, because their margin depends on which model is cheapest this quarter. The difference between a few cents per million input tokens is the difference between profitable and unprofitable for an AI-native company doing high volume.
Enterprises get to amortise. Startups do not. Portability is not a luxury for them, it is a survival trait. Which is why the architectural pattern in this post matters even if you are two people in a garage.
The trick: keep the model on a narrow surface
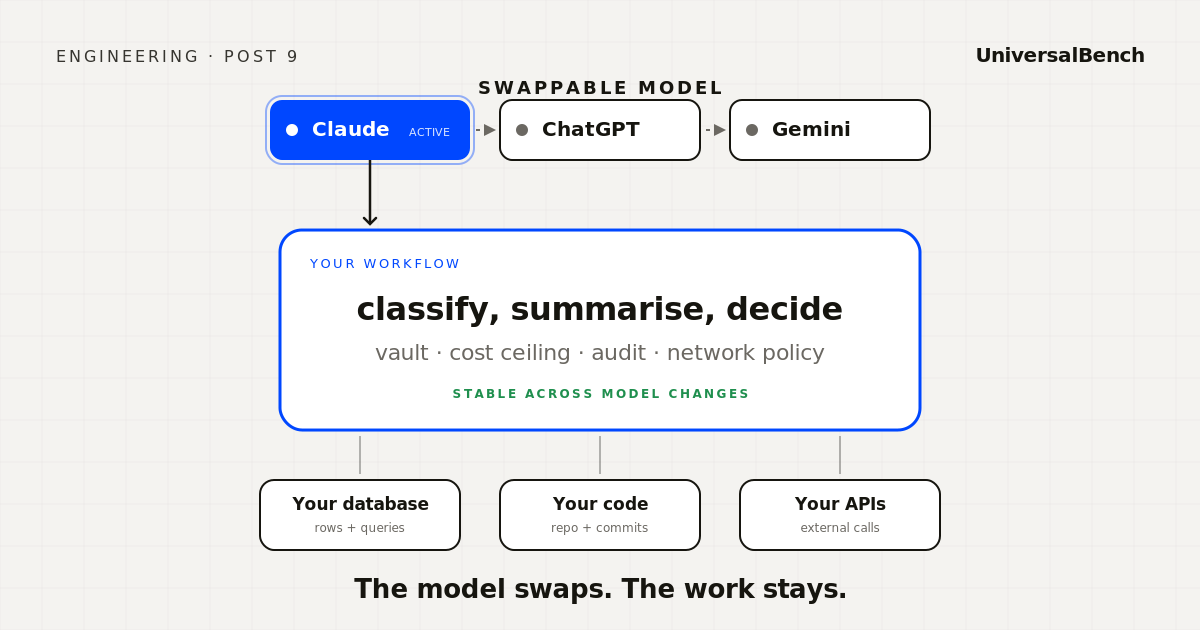
The pattern that works is to give the model the smallest surface area you can. Your workflow does its own thing. When it needs the model, it asks for a specific, well-shaped piece of language work. Classify this. Summarise this. Decide between these three options. The model does that piece and hands back a result. Everything else, the data, the credentials, the actions, the network calls, the validation, the audit, lives outside the model.
The narrower the surface, the easier the swap. The narrower the surface, the smaller the prompt cost. The narrower the surface, the safer the system, because there is less for the model to accidentally see and less for it to accidentally do.
Where UniversalBench fits
UniversalBench is one way to keep the model on a narrow surface. You connect a single URL to whichever model you currently use. Your workflow asks the model to think. UB does the rest: a vault that holds your credentials outside the conversation, a cost ceiling that fires before any call, a network policy that scopes outbound traffic to systems you authorised, a validation gate for any code the model produces, and an audit trail of every action with the request that prompted it.
When you switch models, the URL does not change. Your credentials in the vault do not change. Your governance policies do not change. The only thing that changes is which model does the thinking. Works with Claude, ChatGPT, Gemini, and any MCP compatible AI.
This is also the reason this approach is good news for the model providers, not bad news. A boundary that lets startups and enterprises feel safe letting a model touch real systems puts the model in more work, not less. The healthier the market for safe execution, the bigger the market for intelligence on top of it.
Common questions
Different models behave differently. Isn't a workflow inherently tied to one model? The work is, partly. The wiring is not. The work changes shape by maybe 10% when you swap models. The wiring around the model is closer to 90% of what most teams maintain. Build for the work, not for the model's quirks.
Will my Claude prompts work on Gemini byte for byte? Almost never. But the SHAPE of the work survives. A classify task is still a classify task. A summarise task is still a summarise task. The model in the middle changes a few words and a few structural conventions, not the contract of the task.
What about model specific capabilities? If you depend on a capability only one provider has, document the dependency clearly and isolate it. Most of your workflow should not care which model is being used. The small piece that does should be loud about it, so it is easy to find and rewire later.
Should I just pick one model and commit? Picking one is fine. Tying yourself to one architecturally is the trap. The first lets you focus. The second turns every future model release into a rewrite.
A workflow that outlasts the model is also a workflow that is easier to hand off to a colleague, easier to audit, easier to refactor, and easier to migrate when a meaningfully better provider lands. The model gets better. Your work compounds. Nobody loses.
Run your AI on a single URL
One URL. Bring whichever model you prefer today, swap to the next one when it lands. Your credentials, your governance, and your data path stay where they are. First 1,000 calls per month are free, no card required.
Get API key →