If you have spent any time reading about the Model Context Protocol lately, you have seen the headlines. MCP is a security nightmare. MCP is a dead end. Agents can run commands, reach your internal network, and spend your money, and the protocol does almost nothing to stop them. Most of these takes are correct about the danger. Very few of them go on to show what it actually looks like to make it safe.
We are a small team building execution infrastructure for AI agents, and we had to answer this question in real code, not in a blog post. An agent connecting to us can write and run programs, make network calls, and trigger paid model calls. If we got the controls wrong, a single bad instruction could take something down, leak data, or run up a bill. This is what we learned building the guardrails, and why the right place for them is the platform, not the prompt.
Why MCP feels dangerous
The danger is real and it is structural. MCP is a connector standard. It is very good at letting a model reach tools, and by design it does not dictate what those tools are allowed to do. So the moment you connect an agent to anything powerful, running code, hitting a database, calling an API, you have handed a confident, occasionally wrong system the keys to that capability. The protocol is not the problem. The problem is that capability without constraint is always dangerous, whether a human or a model is driving.
Most advice stops here, at naming the fear. The useful question is the next one: what specific controls turn an unconstrained capability into a safe one?
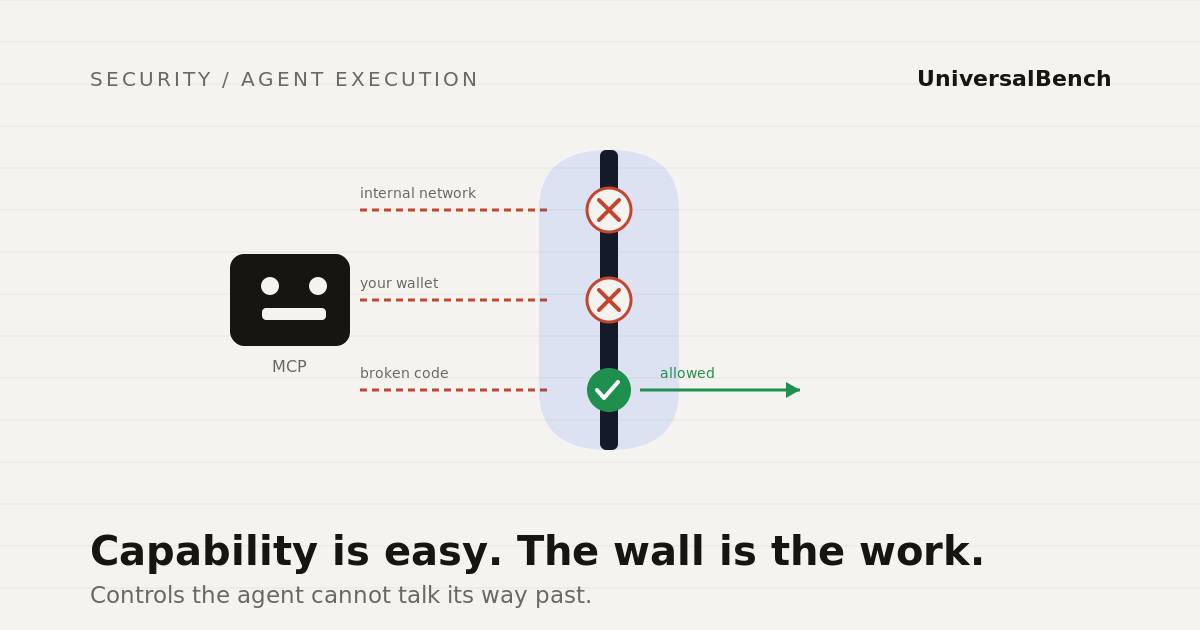
Three fears, three controls
The loudest worries about agent execution fall into three buckets. Each one has a concrete answer that lives below the model, where the agent cannot talk its way around it.
1. It could reach my internal network
The fear: an agent makes an HTTP request to an address it should never touch, a private service, a database on a local IP, a cloud metadata endpoint that hands out credentials. This is the server-side request class of attack, and a model that means no harm can still be tricked into it.
The control is not to ask the model nicely. It is to check every outbound request against a blocklist before it leaves, at the network layer, and refuse anything pointed at private ranges, loopback, link-local, or metadata addresses. The agent cannot opt out because the agent never sees the gate. It just gets a refusal for the addresses it should not reach. The capability stays useful for the public web and dead for everything internal.
2. It could burn my wallet
The fear: an agent loops, retries, or fans out a job and quietly racks up a large bill in model calls before anyone notices. Cost is a security property too, because runaway spend is its own kind of breach.
The control is a hard cap that runs before the spend, not after. Every model call gets cost-estimated first, and any call over the ceiling is rejected rather than executed. A per-call hard limit means no single instruction can blow the budget, no matter how the request is phrased. Again, this lives below the agent. It cannot raise its own ceiling because the ceiling is enforced by the platform, not requested by the prompt.
3. It could ship something broken
The fear: an agent commits code that does not compile or crashes on start, and because the agent reported success, nobody catches it until production does. We wrote a whole separate piece on this in why a green checkmark is not the same as working software.
The control is to validate before the commit lands, confirm the code actually loads, and keep the ability to roll back. The agent does not get to declare victory. The platform confirms it. Broken code is stopped at the gate instead of discovered by your users.
Why these belong in the platform, not the prompt
The instinct, when an agent does something dangerous, is to add a line to the system prompt: do not call internal addresses, do not spend more than X, do not push code that fails. This does not work, and it is important to understand why. A prompt is a request. A confident model under the right pressure will route around a request, or simply forget it ten steps into a task. Anything you can phrase as please do not can be undone by a clever enough instruction or an honest mistake.
A control that lives below the model is different. It is not a request, it is a wall. The agent cannot argue with a network filter that drops the packet, a cost gate that refuses the call, or a validator that blocks the commit. That is the whole difference between security theater and security. If the agent can talk its way past it, it was never a control.
What to actually look for
If you are evaluating any way of giving an AI agent real capability, do not ask whether it is powerful. They are all powerful now. Ask three questions instead. Where do outbound requests get checked, and can the agent bypass that check? What stops a single call or a runaway loop from spending without limit? And what confirms that an action actually succeeded, rather than trusting the agent's own report?
If the honest answer to any of those is "we tell the model not to," that is not a control. The capability and the constraint have to live in the same place, below the agent, where good intentions and clever prompts cannot reach. That is what MCP security actually takes. Not a safer protocol. Safer ground for the protocol to run on.