Open a recent Reddit thread on giving an AI assistant access to a database and you will find advice that boils down to the same shape every time. Paste the connection string, username, and password into your prompt, then tell the model to run queries. The same pattern shows up in tutorial blog posts, GitHub issues, and developer videos. People are doing this, in production, today.
It works. It is also the wrong default. Not because the model is untrustworthy and not because the database is unsafe, but because pasting credentials into a conversation pushes them through surfaces nobody designed to hold them. Browser caches. Provider logs. Screen recordings on a sales call. The first decent prompt injection on a page the model just opened. Once a string is in a prompt, it lives in many more places than you wanted.
The interesting question is not whether your AI should reach your database. For a growing number of useful tasks it should. The interesting question is what should sit between them.
Three properties of a safe boundary
Forget for a moment what tool you would use. Imagine the cleanest description of what a safe boundary between an AI and a database would do. It collapses to three properties.
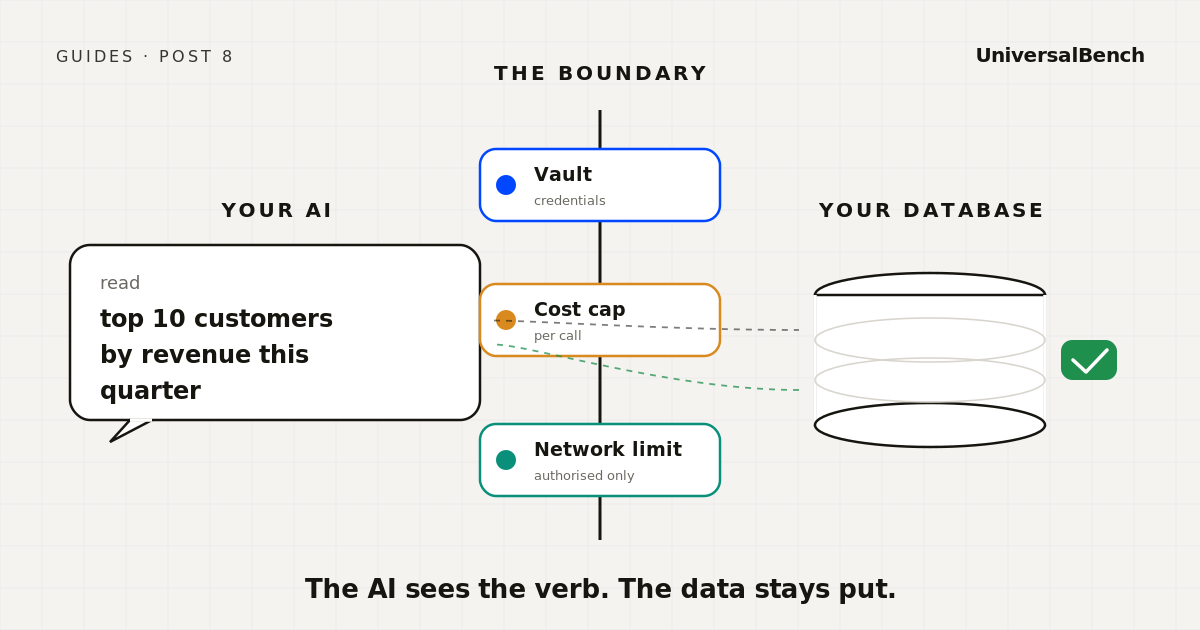
Credentials never enter the conversation
The AI sees a verb. Read these rows. Write this row. The connection string lives somewhere the AI cannot read out loud, and nothing the AI says can extract it.
No single call can quietly become expensive
A runaway query that pulls a million rows costs real money and real database load. A safe boundary refuses the request, or trims it, before the database ever sees it.
The AI cannot reach systems you did not authorise
Your database sits on a private network. Your model lives in a provider data centre on the other side of the world. The boundary keeps the AI scoped to the systems you put behind it, not the rest of your network.
Why this is not your model provider's job
There is a tempting answer to all of this. Surely the model providers will solve it. Anthropic, OpenAI, and Google each have far more engineers than the rest of us combined. They could.
There is a structural reason they probably will not, and it is the same reason a few other categories of infrastructure company exist. The model providers are good at intelligence. Their craft is making the model smarter, faster, and cheaper to run. Building deep, opinionated controls around how that model interacts with your specific systems, with your specific budget, and with your specific compliance posture, is a different specialism. The same way large platforms tend to leave payments to companies that specialise in payments, and observability to companies that specialise in observability, even when in principle they could have built either.
This is also why the safest patterns are quietly neutral on which model you pick. The boundary between an AI and your database does not need to know which company trained the AI. The data still lives where it lives. The credentials are yours. The network rules are yours. The cost ceiling is yours. None of those facts should change when you decide to try a different model next quarter.
The model and the data both win when the boundary exists
A boundary that genuinely works is good news for the model provider and good news for the database provider, not bad news.
The model provider sells more usage when their customers feel safe letting their model touch real systems. The biggest blocker to enterprise AI adoption right now is not whether the model is capable. It is whether the people responsible for production systems will hand the model the keys. A trustworthy boundary lowers that bar. The model gets invited into more work. That is more requests, not fewer.
The database provider, in the same way, makes more money when AI mediated usage of their data is welcomed rather than feared. An AI that can safely query a managed Postgres instance for legitimate business questions ends up running more queries against more rows than a human alone would have thought to ask. The provider's product expands rather than shrinks.
The customer benefits because they keep optionality. They are not locked to one model. They are not locked to one database. The decision they made today is reversible tomorrow.
What this looks like in practice
You store the connection string for your database in a vault that lives outside the conversation. You connect the AI of your choice to a single endpoint that knows how to ask your vault for those credentials when, and only when, the AI requests a specific database action. The AI requests an action. The boundary checks the request against your rules. The boundary asks the vault for the credentials, runs the action, and returns the result.
The AI sees the result. It does not see the credentials. It cannot accidentally print them. A prompt injection on a page the AI just read cannot exfiltrate them either, because they were never in the model's context to begin with.
Two extras make this safer still. A cost ceiling that fires before the model is even asked to spend, so a runaway loop never gets the chance to drain your budget. And a network policy that refuses outbound traffic to anything the customer did not put behind the boundary. Together with the vault, those are the three properties named above, working as one system rather than three isolated checks.
Where UniversalBench fits
UniversalBench is one implementation of this pattern. You connect a single URL to whichever AI you already use, store your database credentials once, and the three properties above are on by default. Your model of choice can read and write to your database without ever seeing the connection string. The cost ceiling fires before the call. The network policy keeps the model's reach scoped to the systems you authorised.
We do not replace your AI. We do not replace your database. The whole point is that you keep both, and that the layer in between is something your team controls and that survives whichever model you decide to use next quarter. Works with Claude, ChatGPT, Gemini, and any MCP compatible AI. If you have not yet wired one up, the connect guide walks through it.
Common questions
Why not just use a read only database user and call it a day? A read only user reduces the blast radius of a runaway query, but it does not change the credential problem. The connection string still has to live somewhere. If it lives in your prompt, it lives wherever your prompt logs end up. A boundary that holds the credential outside the conversation is the part that fixes the structural issue.
What if I want my AI to write, not just read? The boundary still works. The pattern does not depend on the action being read only. You can scope writes to specific tables, require a validation step before commit, or wrap writes in a transaction the boundary can roll back when a smoke check fails. The verbs become richer. The credential stays put.
Will this slow my AI down? The boundary adds a small amount of overhead per call. In practice, what slows agents down is the back and forth chatter when the model has to describe what it would do instead of doing it. Letting the AI take an action and receive a result in one step is faster overall.
What if I want to change my AI provider? That is the whole point of having a boundary that is neutral. The credentials stay in the vault. The rules stay in the boundary. The endpoint your AI connects to does not change. You change the AI.
A safe boundary is not glamorous engineering. It is not what gets you on the front page of a release announcement. It is the thing that, once it exists, makes the rest of the work safe to do. The right time to put it in place is before you need it, not after a credential string ends up somewhere it should not have.
Try the pattern
One URL, your AI of choice, your credentials in a vault the model cannot read out loud. First 1,000 calls per month are free, no card required.
Get API key →