When an AI agent handles a complex task, the default approach is to send everything to the model: the raw data, the search results, the logs, all of it. The model reads it, processes it, and returns an answer. This works. It also gets expensive fast.
At 10,000 queries per day, the difference between sending 4,024 tokens and 141 tokens is not a footnote. It is the difference between $42,519 per year and $5,988 per year. That is a single architectural decision with a 610% ROI impact.
We built a platform around this idea. Then we tested it properly. What follows are three real API calls, each run with and without the platform. No adjustments. No cherry-picking. Every number published.
Test setup and methodology
All three tests used the same model. We called the API directly. The results are verifiable. We are not asking you to trust our word. Run the same tests and check the numbers yourself.
Test 1: When the model simply cannot do it
The first test was about capability, not token cost. We asked the model a question that requires live web access: retrieve current information about a real-world topic.
Token cost comparison is irrelevant when one path produces an answer and the other produces a refusal. Some tasks are simply not possible any other way.
Test 2: When cheaper is also more accurate
We gave the model two deterministic maths problems: find the largest prime under 10,000, and find the largest gap between consecutive primes up to 10,000. These have exact, verifiable correct answers.
Said the largest prime gap was 20. Wrong. Correct answer is 36. A 44% error.
30% fewer tokens than the incorrect attempt.
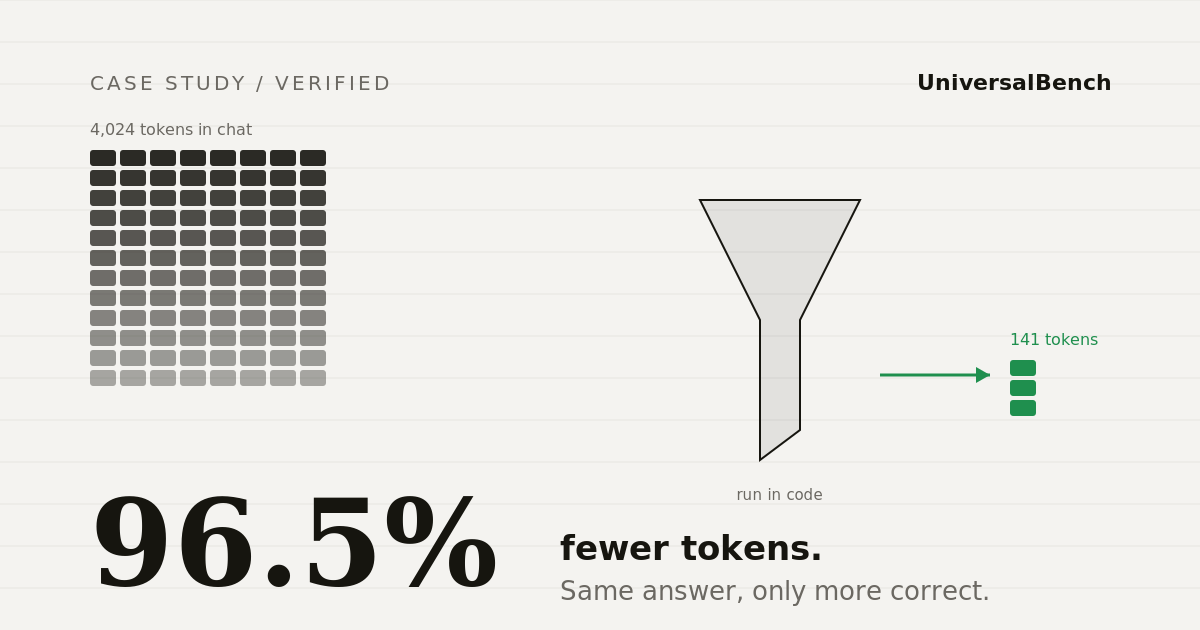
Test 3: The 96.5% reduction
We gave the model a log file and asked it to count the number of errors. The correct answer is 41.
Model reported 37 errors. Wrong. Correct answer is 41.
Result: 41 errors. Correct.
What this means at scale
| Volume | Without platform | With platform | Annual saving |
|---|---|---|---|
| 1,000 queries / day | $4,252 / yr | $599 / yr | $3,653 |
| 10,000 queries / day | $42,519 / yr | $5,988 / yr | $36,531 |
| ROI at 10k / day | 610% |
How it works
The platform sits between your AI and the data it would otherwise need to read. Before the model sees the task, the platform runs code, searches the web, queries databases, and commits to GitHub. The model gets the answer, not the raw material to compute it.
Code execution
Count records, process data, parse files. The model receives the result, not the file.
Web search
Retrieve current information before it reaches the model. Real data instead of a refusal.
Database queries
Filter, aggregate, and return exact rows. The model gets the result, not the whole table.
Cost caps built in
Every call is estimated before it runs. Calls over your ceiling are rejected by default.
One URL. Connect your agent once. Works with Claude, ChatGPT, Gemini, or any MCP-compatible model. Every new capability reaches your AI automatically on the next call.
Related reading
If you care about token cost, you probably also care about what the platform does to the code your agent ships. See AI Never Ships Broken Code for how every commit is confirmed to load before it lands.
Estimate your own saving
Plug in your numbers to see what your tokens cost per year and how much you keep by moving the heavy work out of the chat.
Estimate only, at $3.00 per million input tokens. The 96.5 percent figure is a measured result on a data-heavy log task, not a guarantee for every query.
Open the full calculator →Start free. Check the numbers yourself.
1,000 free calls per month. One URL. Any MCP-compatible AI agent.
Get your API key