There is a lot of advice going around about cutting your AI agent's token bill. Shorten the system prompt. Compress the tool schemas. Cap the number of tools. Use cheaper models for the easy turns. All of it helps a little. None of it touches the thing that is actually costing you the most.
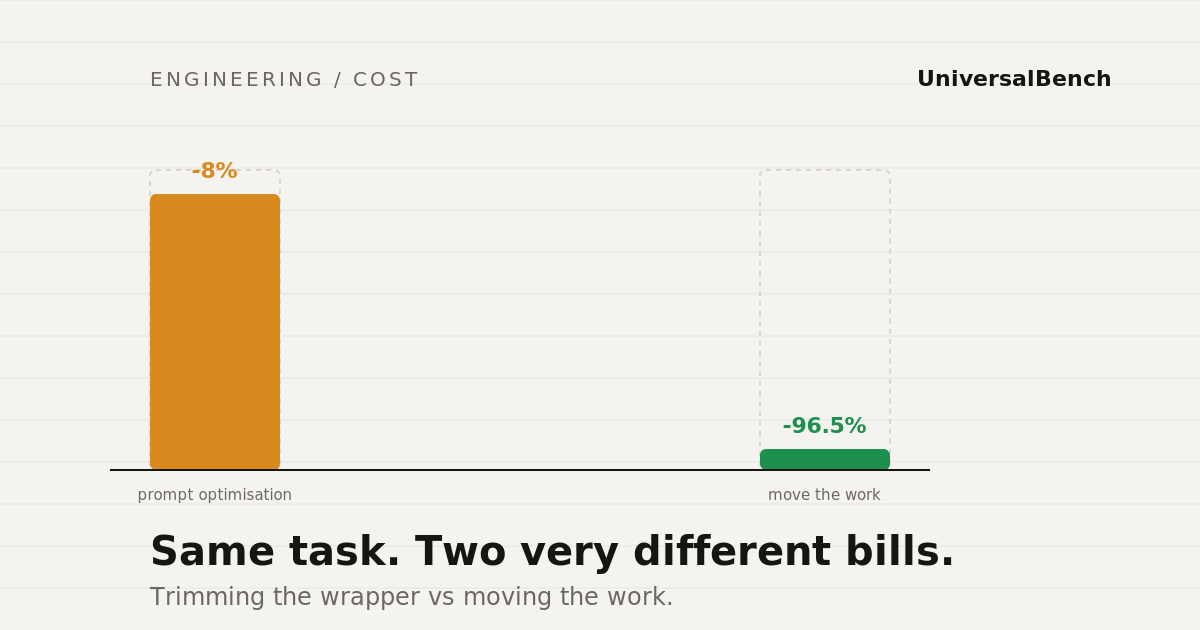
We learned this building our own platform. We chased prompt optimisation for a while, shaving words, trimming examples, deduplicating schema fields. The savings were real but small, the kind of single digit percentages that feel like progress until you look at the bill. Then we changed where the work happened instead of how we worded it, and the same task dropped by 96.5 percent. This post is about why that gap exists, and why the bigger lever is the one most teams skip.
The token bill has two halves
When people say their agent is expensive, they usually mean one of two different costs, and the fixes are not the same.
The first is schema cost. Every tool you connect ships its full definition into the model's context on each request. Connect a handful of busy servers and tool definitions alone can eat a large slice of your context window before the agent has done anything. This is the cost prompt optimisation and schema compression go after, and yes, trimming it back helps.
The second is work cost. This is the tokens spent doing the actual task: pulling a big document into context to summarise it, loading thousands of log lines so the model can count errors, reading an entire file to change one line. This is almost always the larger number, and prompt optimisation does nothing for it. You can compress every schema you own and still pay full price to drag a 4,000 line log through the model.
Why prompt optimisation hits a ceiling
Prompt and schema optimisation works on the overhead, the framing around the task. There is a floor to how small that overhead can get, because the model still needs to understand what it can do. Once you have trimmed the fat, you are done, and you are still paying the work cost in full.
Think of it like trying to lower a grocery bill by using smaller bags. The bags are not the expense. The groceries are. Optimising the wrapper around the work cannot reduce the work itself.
Where the real reduction comes from
The large savings come from not moving the raw material through the model at all. Instead of loading 4,000 log lines into context so the model can count errors, you run a few lines of code where the logs already are, and return only the answer: 41 errors. The model never sees the bulk data. It sees the result.
This is the difference between asking someone to read you an entire spreadsheet so you can find a total, versus handing them a calculator and asking for the total. Same answer. A fraction of the words.
We measured this directly. On a log analysis task, doing the work in chat cost 4,024 input tokens and the model still got the count wrong. Doing the same work in code cost 141 tokens and got it right. That is a 96.5 percent reduction, and it came from moving the work, not rewording the request. We published every number behind that test in our token costs breakdown if you want to check it yourself.
Why fewer tools beats compressed tools
The same logic applies to the schema half of the bill. The popular fix is to compress tool definitions or limit how many load at once. A better fix is to not expose dozens of tools in the first place. If the model reaches a single endpoint and the capabilities live behind it, the context cost stays flat no matter how much the platform can actually do. You are not choosing between a slim schema and a rich one. You are moving the richness out of the context window entirely.
This also fixes a problem compression does not: tool selection. When an agent can see forty tools, it picks the wrong one more often. Fewer choices in context means fewer wrong turns, which means fewer retries, which is itself a token saving nobody counts.
What to actually do
Prompt optimisation is still worth doing. Tighten your system prompt, drop redundant examples, do not connect tools you do not use. Treat it as housekeeping, not as your cost strategy.
For the real number, ask a different question of every expensive task: does the model need to see this data, or just the answer derived from it? Anywhere the honest answer is "just the answer," that work belongs in code, running where the data already is, returning a result instead of a payload. That single shift is where the order of magnitude lives.
Smaller prompts make a cheaper wrapper. Moving the work makes a cheaper bill. They are not the same lever, and only one of them is large.
Estimate your own saving
Plug in your numbers to see what your tokens cost per year and how much you keep by moving the heavy work out of the chat.
Estimate only, at $3.00 per million input tokens. The 96.5 percent figure is a measured result on a data-heavy log task, not a guarantee for every query.
Open the full calculator →