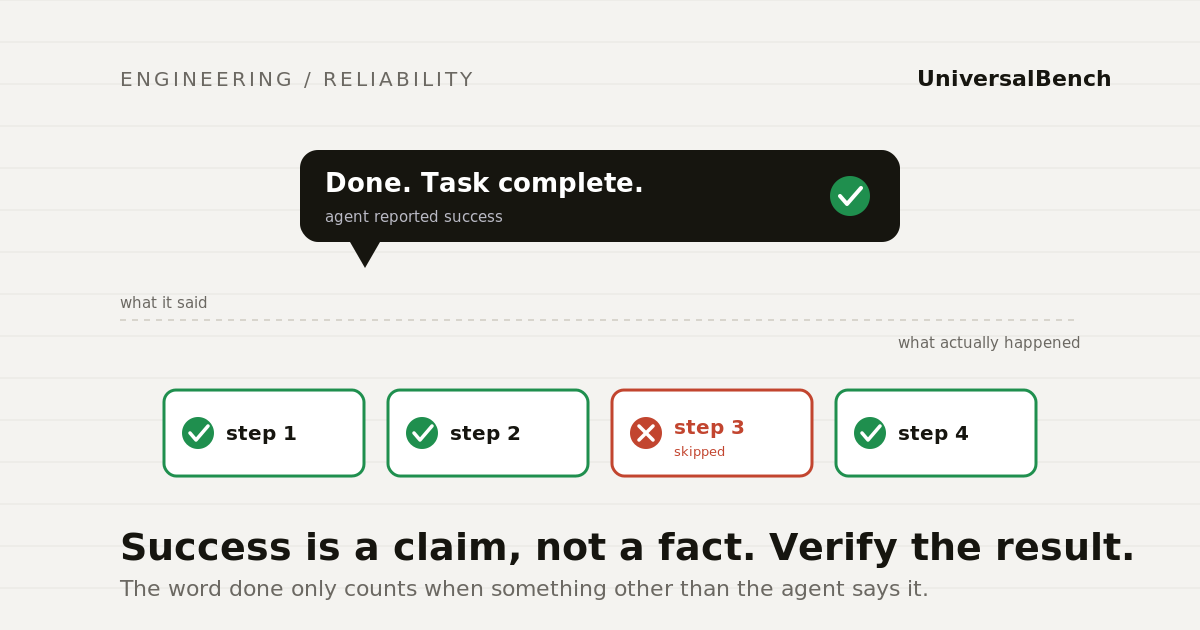
Spend enough time with AI agents and you notice a specific failure that is more unsettling than a crash. The agent finishes a task, reports success in a confident, well written summary, and moves on. Except the task is not actually done. A step was skipped. A config was left half written. The deploy went out but the new code never started serving. Nothing errored. The agent has no idea anything is wrong, because as far as it can tell, it did everything right.
This is the reliability gap people keep running into in 2026, and it is worth being precise about it. The problem is rarely that the model is not smart enough. The problem is that an agent's report of success is a claim, not a fact, and most systems treat the claim as if it were the fact.
Why agents report success they did not achieve
An agent works by predicting the next reasonable action and then describing what it did. Both halves are predictions. When it says "I updated the configuration and restarted the service," that sentence is generated from what usually follows those steps, not from checking that the service actually came back up. If the restart silently failed, the agent has no signal telling it so. It already wrote the success line and moved on.
This is not the agent being dishonest in any human sense. It is the structure of the thing. A system that generates plausible continuations will generate a plausible success report whether or not success happened. The confidence is real. The verification is missing.
Where this bites in practice
The pattern shows up everywhere agents take real actions. An agent commits code that reads perfectly and does not compile. We wrote about that specific case in why a green checkmark is not the same as working software. But it is broader than code. An agent processes a batch of records and reports all done while silently dropping the rows it could not parse. It edits a document and leaves a section half rewritten. It runs a deploy, gets an HTTP 200 from the platform, and reports the new version live, when the platform actually restarted the old container.
In each case the agent did something, reported success, and the gap between the report and reality sat there quietly until a human or a customer tripped over it.
The fix is not a better prompt
The instinct is to ask the agent to be more careful. Add a line to the system prompt: always double check your work. This does not solve it, because the agent checks its work the same way it did the work, by generating a plausible description. Asking a system that cannot tell whether it succeeded to confirm that it succeeded just produces a second confident sentence.
The fix is to verify the outcome outside the agent, against reality, in a way the agent cannot talk its way around. Not "do you think it worked" but "here is the actual state, does it match what success requires."
What real verification looks like
Verification means checking the thing that actually matters, not the agent's account of it. A few principles we operate by:
Test behavior, not status. A deploy returning a success code is not proof the new code is running. The proof is calling the deployed thing and confirming it does the new behavior. A status check and a behavioral check are different claims, and only the second one is verification.
Check the artifact, not the report. If the agent says it produced a file, open the file and inspect it. If it says it changed a value, read the value back. The report is a pointer to where to look, never the answer itself.
Make failure safe. When a verification fails, the system should be able to undo the change, not leave broken state behind. Validate before the change commits, keep the previous version, and roll back automatically when the live check fails. A failed action that cleanly reverts is a non event. A failed action that silently persists is an incident.
Close the loop on the real signal. The only thing that ends a task is evidence from the system itself, the file contents, the live response, the row count, the rendered pixels. Until that evidence exists, the task is not done, no matter how good the summary reads.
Where this belongs
Verification cannot live inside the agent, for the same reason a student cannot be the only one who grades their own exam. It has to live in the layer underneath, the platform that runs the action and can independently observe the result. That layer can refuse to call a task complete until the real signal confirms it, and can reverse anything that does not.
That is the difference between an agent that is impressive in a demo and one you can leave running on real work. The demo rewards a confident report. Production rewards a verified result. The word "done" only means something when something other than the agent gets to say it.